Turn Parallel Processing Off and Run Sequentially Again
20
Agreement Parallel Execution Performance Issues
This chapter provides a conceptual explanation of parallel execution performance problems, and additional functioning techniques.
- Understanding Parallel Execution Performance Issues
- Parallel Execution Tuning Techniques
See Besides: Oracle8 Concepts, for basic principles of parallel execution.
See your operating arrangement-specific Oracle documentation for more data nearly tuning while using parallel execution.
Understanding Parallel Execution Performance Problems
- The Formula for Memory, Users, and Parallel Server Processes
- Setting Buffer Puddle Size for Parallel Operations
- How to Balance the Formula
- Examples: Balancing Memory, Users, and Processes
- Parallel Execution Space Management Bug
- Optimizing Parallel Execution on Oracle Parallel Server
The Formula for Memory, Users, and Parallel Server Processes
Key to the tuning of parallel operations is an understanding of the human relationship between memory requirements, the number of users (processes) a system can support, and the maximum number of parallel server processes. The goal is to obtain the dramatic functioning enhancement fabricated possible by parallelizing certain operations, and by using hash joins rather than sort merge joins. This performance goal must oftentimes be balanced with the need to back up multiple users.
In considering the maximum number of processes a system can support, it is useful to divide the processes into iii classes, based on their retention requirements. Table xx-1 defines high, medium, and low memory processes.
Clarify the maximum number of processes that can fit in memory as follows:
Effigy 20-1 Formula for Memory/Users/Server Relationship
Table 20-one Memory Requirements for 3 Classes of Process
| Class | Clarification |
|---|---|
| Low Memory Processes: 100K to 1MB | These processes include tabular array scans; index lookups; index nested loop joins; single-row aggregates (such as sum or average with no Grouping BYs, or very few groups); sorts that return only a few rows; and direct loading. This course of Data Warehousing process is similar to OLTP processes in the corporeality of memory required. Process memory could be as depression as a few hundred kilobytes of fixed overhead. Yous could potentially back up thousands of users performing this kind of operation. You can take this requirement even lower past using the multithreaded server, and back up even more than users. |
| Medium Retentivity Processes: 1MB to 10MB | This form of process includes large sorts; sort merge join; GROUP By or Lodge BY operations returning a large number of rows; parallel insert operations which involve index maintenance; and index creation. These processes require the stock-still overhead needed by a low memory process, plus one or more sort areas, depending on the operation. For example, a typical sort merge join would sort both its inputs-resulting in two sort areas. GROUP By or ORDER Past operations with many groups or rows also require sort areas. Look at the EXPLAIN PLAN output for the operation to identify the number and type of joins, and the number and type of sorts. Optimizer statistics in the plan show the size of the operations. When planning joins, remember that y'all practise accept a number of choices. |
| Loftier Retentivity Processes: 10MB to 100MB | High memory processes include one or more hash joins, or a combination of one or more hash joins with large sorts. These processes require the fixed overhead needed by a low retentivity process, plus hash surface area. The hash expanse size required might range from 8MB to 32MB, and you might need two of them. If y'all are performing 2 or more than serial hash joins, each process uses 2 hash areas. In a parallel operation, each parallel server process does at most 1 hash bring together at a time; therefore, you would demand one hash area size per server. In summary, the corporeality of hash bring together retention for an functioning equals parallel caste multiplied by hash area size, multiplied by the lesser of either 2, or the number of hash joins in the performance. |
Note: The process retentiveness requirements of parallel DML and parallel DDL operations also depend upon the query portion of the statement.
Setting Buffer Pool Size for Parallel Operations
The formula whereby you tin summate the maximum number of processes your system tin back up (referred to here as max_processes) is: 
In general, if max_processes is much bigger than the number of users, y'all can consider running parallel operations. If max_processes is considerably less than the number of users, yous must consider other alternatives, such every bit those described in "How to Rest the Formula" on page 20-5.
With the exception of parallel update and delete, parallel operations do non generally benefit from larger buffer puddle sizes. Parallel update and delete benefit from a larger buffer pool when they update indexes. This is because index updates have a random access pattern and I/O activity can be reduced if an entire index or its interior nodes can be kept in the buffer pool. Other parallel operations tin benefit only if the buffer pool can be made larger and thereby accommodate the inner tabular array or alphabetize for a nested loop join.
- Encounter Too: Oracle8 Concepts for a comparison of hash joins and sort merge joins.
- "Tuning the Buffer Enshroud" on page fourteen-26 on setting buffer pool size.
How to Balance the Formula
Apply the post-obit techniques to balance the memory/users/server formula given in Effigy 20-i:
- Oversubscribe, with Attention to Paging
- Reduce the Number of Retentivity-Intensive Processes
- Subtract Information Warehousing Memory per Process
- Decrease Parallelism for Multiple Users
Oversubscribe, with Attention to Paging
You can permit the potential workload to exceed the limits recommended in the formula. Total memory required, minus the SGA size, tin can exist multiplied by a factor of ane.2, to let for 20% oversubscription. Thus, if y'all have 1G of memory, you might be able to back up 1.2G of demand: the other xx% could be handled by the paging organization.
Y'all must, however, verify that a particular degree of oversubscription volition be viable on your system by monitoring the paging charge per unit and making certain y'all are non spending more than a very small pct of the time waiting for the paging subsystem. Your system may perform passably even if oversubscribed by lx%, if on average not all of the processes are performing hash joins concurrently. Users might then endeavor to use more the available memory, and then you lot must monitor paging action in such a state of affairs. If paging goes up dramatically, consider another alternative.
On boilerplate, no more than 5% of the fourth dimension should be spent only waiting in the operating system on page faults. More than 5% wait time indicates an I/O bound paging subsystem. Use your operating system monitor to check expect time: The sum of time waiting and time running equals 100%. If you are running shut to 100% CPU, so yous are not waiting. If you are waiting, information technology should not be on account of paging.
If expect time for paging devices exceeds 5%, it is a strong indication that you must reduce memory requirements in one of these ways:
- Reducing the memory required for each class of process
- Reducing the number of processes in memory-intensive classes
- Adding memory
If the wait time indicates an I/O bottleneck in the paging subsystem, you lot could resolve this by striping.
Reduce the Number of Memory-Intensive Processes
Adjusting the Caste of Parallelism. You tin can accommodate not merely the number of operations that run in parallel, but also the caste of parallelism with which operations run. To do this, issue an ALTER TABLE statement with a PARALLEL clause, or use a hint. Run into the Oracle8 SQL Reference for more than information.
You tin limit the parallel puddle by reducing the value of PARALLEL_MAX_SERVERS. Doing so places a arrangement-level limit on the total amount of parallelism, and is easy to administrate. More than processes are then forced to run in serial mode.
Scheduling Parallel Jobs. Queueing jobs is another style to reduce the number of processes but not reduce parallelism. Rather than reducing parallelism for all operations, you may be able to schedule large parallel batch jobs to run with total parallelism one at a fourth dimension, rather than concurrently. Queries at the head of the queue would accept a fast response fourth dimension, those at the end of the queue would take a boring response fourth dimension. Still, this method entails a certain amount of administrative overhead.
Decrease Data Warehousing Memory per Process
Note: The following discussion focuses upon the relationship of HASH_AREA_SIZE to retention, but nevertheless considerations apply to SORT_AREA_SIZE. The lower leap of SORT_AREA_SIZE, however, is not as critical as the 8MB recommended minimum HASH_AREA_SIZE.
If every operation performs a hash join and a sort, the high memory requirement limits the number of processes you tin can accept. To let more users to run meantime you may demand to reduce the DSS process memory.
Moving Processes from High to Medium Retentiveness Requirements. You can move a process from the high-memory to the medium-memory class by irresolute from hash join to merge join. You can use initialization parameters to limit available memory and thus force the optimizer to stay within certain bounds.
To do this, you can reduce HASH_AREA_SIZE to well below the recommended minimum (for example, to ane or 2MB). And so you can let the optimizer choose sort merge join more oft (as opposed to telling the optimizer never to use hash joins). In this way, hash join can withal be used for small tables: the optimizer has a retentivity upkeep within which information technology can brand decisions about which bring together method to employ. Alternatively, you can apply hints to forcefulness simply certain queries (those whose response fourth dimension is non critical) to use sort-merge joins rather than hash joins.
Remember that the recommended parameter values provide the best response time. If you severely limit these values you lot may run across a significant effect on response time.
Moving Processes from High or Medium Memory Requirements to Low Memory Requirements. If you need to support thousands of users, you must create admission paths such that operations do not touch much information.
- Decrease the demand for index joins by creating indexes and/or summary tables.
- Decrease the demand for Grouping By sorting by creating summary tables and encouraging users and applications to reference summaries rather than detailed data.
- Subtract the need for ORDER BY sorts by creating indexes on frequently sorted columns.
Subtract Parallelism for Multiple Users
In full general in that location is a merchandise-off betwixt parallelism for fast single-user response fourth dimension and efficient use of resources for multiple users. For example, a system with 2G of memory and a HASH_AREA_SIZE of 32MB tin can support about 60 parallel server processes. A 10 CPU machine can support up to iii concurrent parallel operations (2 * ten * iii = sixty). In lodge to support 12 concurrent parallel operations, you could override the default parallelism (reduce it); decrease HASH_AREA_SIZE; buy more retention, or utilise some combination of these 3 strategies. Thus you could Alter TABLE t PARALLEL (Degree 5) for all parallel tables t, set HASH_AREA_SIZE to 16MB, and increase PARALLEL_MAX_SERVERS to 120. By reducing the memory of each parallel server by a factor of 2, and reducing the parallelism of a single operation by a factor of 2, the system tin can accommodate 2 * ii = 4 times more than concurrent parallel operations.
The penalty for taking such an approach is that when a single performance happens to be running, the organization will use merely half the CPU resources of the 10 CPU motorcar. The other half will be idle until another operation is started.
To determine whether your system is existence fully utilized, you tin apply ane of the graphical system monitors available on near operating systems. These monitors oftentimes requite you a improve idea of CPU utilization and system operation than monitoring the execution time of an performance. Consult your operating system documentation to make up one's mind whether your system supports graphical system monitors.
Examples: Balancing Memory, Users, and Processes
The examples in this section show how to evaluate the relationship between retentiveness, users, and parallel server processes, and balance the formula given in Figure 20-1. They show concretely how you lot might adjust your organization workload so as to accommodate the necessary number of processes and users.
Example 1
Assume that your system has 1G of memory, the caste of parallelism is 10, and that your users perform two hash joins with 3 or more tables. If you demand 300MB for the SGA, that leaves 700MB to adjust processes. If you allow a generous hash area size (32MB) for all-time performance, then your arrangement can back up:
- 1 parallel operation (32MB * 10 * ii = 640MB)
- 1 serial operation (32MB * 2 = 64MB)
This makes a total of 704MB. (Notation that the memory is not significantly oversubscribed.)
Call back that every parallel, hash, or sort merge bring together operation takes a number of parallel server processes equal to twice the caste of parallelism (utilizing 2 server sets), and often each individual procedure of a parallel operation uses a lot of retention. Thus y'all tin back up many more users past having them run serially, or past having them run with less parallelism.
To service more users, you lot can drastically reduce hash area size to 2MB. Y'all may then notice that the optimizer switches some operations to sort merge join. This configuration tin back up 17 parallel operations, or 170 serial operations, but response times may be significantly higher than if you lot were using hash joins.
Notice the trade-off above: by reducing memory per process past a factor of sixteen, yous can increment the number of concurrent users by a factor of 16. Thus the amount of concrete retentiveness on the machine imposes another limit on total number of parallel operations you can run involving hash joins and sorts.
Case ii
In a mixed workload example, consider a user population with various needs, as described in Table twenty-two. In this situation, you lot would take to make some choices. You could not let everyone to run hash joins-even though they outperform sort merge joins-because you lot do not accept the memory to support this level of workload.
Yous might consider it safe to oversubscribe at l% because of the infrequent batch jobs during the 24-hour interval: 700MB * 1.v = one.05GB. This would give you enough virtual memory for the total workload.
Table 20-2 How to Accommodate a Mixed Workload
| User Needs | How to Accommodate |
|---|---|
| DBA: runs nightly batch jobs, and occasional batch jobs during the day. These might exist parallel operations that practice hash joins that use a lot of memory. | Y'all might accept 20 parallel server processes, and gear up HASH_AREA_SIZE to a mid-range value, perhaps 20MB, for a single powerful batch job in the high memory class. (This might exist a large GROUP Past with join to produce a summary of data.) Twenty servers multiplied by 20MB equals 400MB of memory. |
| Analysts: interactive users who pull data into their spreadsheets | Yous might plan for 10 analysts running serial operations that use complex hash joins accessing a big amount of data. (You would not let them to do parallel operations because of memory requirements.) Ten such series processes at 40MB apiece equals 400MB of memory. |
| Users: Several hundred users doing simple lookups of individual customer accounts, making reports on already joined, partially summarized data | To back up hundreds of users doing low memory processes at nearly 0.5MB apiece, you might reserve 200MB. |
Case three
Suppose your organisation has 2G of retentiveness, and yous take 200 parallel server processes and 100 users doing heavy information warehousing operations involving hash joins. You lot decide to leave such tasks every bit index retrievals and small sorts out of the picture, concentrating on the high memory processes. Yous might have 300 processes, of which 200 must come up from the parallel pool and 100 are single threaded. One quarter of the total 2G of memory might be used by the SGA, leaving one.5G of memory to handle all the processes. Yous could apply the formula considering only the high memory requirements, including a gene of 20% oversubscription:
Figure twenty-2 Formula for Memory/User/Server Relationship: High-Memory Processes
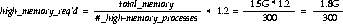
Hither, 5MB = one.8G/300. Less than 5MB of hash area would be bachelor for each process, whereas 8MB is the recommended minimum. If you must take 300 processes, you lot may need to force them to utilize other join methods in order to change them from the highly memory-intensive course to the moderately memory-intensive class. Then they may fit within your arrangement'south constraints.
Example 4
Consider a system with 2G of memory and 10 users who want to run intensive information warehousing parallel operations concurrently and still take good performance. If you cull parallelism of degree 10, then the 10 users will require 200 processes. (Processes running big joins need twice the number of parallel server processes as the degree of parallelism, so you would prepare PARALLEL_MAX_SERVERS to x * x * 2.) In this case each procedure would get 1.8G/200-or about 9MB of hash area-which should exist adequate.
With only 5 users doing large hash joins, each process would get over 16MB of hash area, which would be fine. But if yous want 32MB available for lots of hash joins, the organisation could only back up two or three users. By contrast, if users are merely computing aggregates the system needs adequate sort area size-and can accept many more than users.
Example five
If a arrangement with 2G of retentiveness needs to back up 1000 users, all of them running large operations, you must evaluate the situation carefully. Here, the per-user memory budget is only 1.8MB (that is, 1.8G divided past 1,000). Since this figure is at the low stop of the medium memory process form, you lot must rule out parallel operations, which use fifty-fifty more resource. You must also rule out big hash joins. Each sequential procedure could crave upwardly to 2 hash areas plus the sort area, so you would have to prepare HASH_AREA_SIZE to the aforementioned value as SORT_AREA_SIZE, which would be 600K (one.8MB/3). Such a pocket-sized hash area size is likely to be ineffective, so you may opt to disable hash joins altogether.
Given the system's resources and business needs, is information technology reasonable for you to upgrade your arrangement'south retentiveness? If retention upgrade is non an option, then you must change your expectations. To adapt the remainder you might:
- Accept the fact that the organization will actually support a limited number of users doing big hash joins.
- Expect to support the 1000 users doing index lookups and joins that do not require big amounts of memory. Sort merge joins crave less memory, but throughput will go down because they are not equally efficient as hash joins.
- Give the users access to summary tables, rather than to the whole database.
- Classify users into different groups, and give some groups more retention than others. Instead of all users doing sorts with a small sort surface area, you lot could have a few users doing high-memory hash joins, while most users apply summary tables or do low-retentivity alphabetize joins. (Y'all could achieve this past forcing users in each group to apply hints in their queries such that operations are performed in a particular way.)
Parallel Execution Space Management Problems
This department describes infinite management issues that come into play when using parallel execution.
- ST (Space Transaction) Enqueue for Sorts and Temporary Data
- External Fragmentation
These issues become specially important for parallel operation running on a parallel server, the more than nodes involved, the more tuning becomes critical.
ST (Infinite Transaction) Enqueue for Sorts and Temporary Data
Every infinite direction transaction in the database (such as cosmos of temporary segments in PARALLEL CREATE Table, or parallel direct-load inserts of not-partitioned tables) is controlled by a single ST enqueue. A loftier transaction rate (more than 2 or 3 per minute) on the ST enqueue may result in poor scalability on Oracle Parallel Server systems with many nodes, or a timeout waiting for infinite management resources.
Try to minimize the number of space management transactions, in particular:
- the number of sort space direction transactions
- the creation and removal of objects
- transactions caused by fragmentation in a tablespace.
Employ defended temporary tablespaces to optimize infinite management for sorts. This is especially beneficial on a parallel server. You lot can monitor this using 5$SORT_SEGMENT.
Ready INITIAL and Side by side extent size to a value in the range of 1MB to 10MB. Processes may use temporary infinite at a charge per unit of up to 1MB per 2nd. Do non take the default value of 40K for next extent size, considering this will result in many requests for infinite per second.
If you are unable to allocate extents for various reasons, you can recoalesce the space by using the ALTER TABLESPACE ... Coagulate Space control. This should be done on a regular basis for temporary tablespaces in particular.
See Too: "Setting Upwardly Temporary Tablespaces for Parallel Sort and Hash Join" on page nineteen-forty
External Fragmentation
External fragmentation is a business organisation for parallel load, direct-load insert, and PARALLEL CREATE TABLE ... AS SELECT. Retentiveness tends to become fragmented every bit extents are allocated and data is inserted and deleted. This may event in a off-white amount of free space that is unusable because it consists of small, non-face-to-face chunks of retention. To reduce external fragmentation on partitioned tables, set all extents to the aforementioned size. Set up MINEXTENTS to the same value as Adjacent, which should exist equal to INITIAL; set PERCENT_INCREASE to zero. The system can handle this well with a few thousand extents per object, so you lot tin set up MAXEXTENTS to a few 1000. For tables that are not partitioned, the initial extent should be small.
Optimizing Parallel Execution on Oracle Parallel Server
This section describe several aspects of parallel execution on Oracle Parallel Server.
Lock Allocation
This section provides parallel execution tuning guidelines for optimal lock management on Oracle Parallel Server.
To optimize parallel execution on Oracle Parallel Server, y'all demand to correctly set GC_FILES_TO_LOCKS. On Oracle Parallel Server a sure number of parallel cache direction (PCM) locks are assigned to each data file. Data block accost (DBA) locking in its default behavior assigns one lock to each block. During a full table scan a PCM lock must and so be acquired for each block read into the scan. To speed up total tabular array scans, you have three possibilities:
- For data files containing truly read-only data, set the tablespace to read but. Then there will exist no PCM locking at all.
- Alternatively, for data that is mostly read-just, assign very few hashed PCM locks (for example, 2 shared locks) to each information file. Then these will be the only locks you have to larn when yous read the data.
- If yous want DBA or fine-grain locking, group together the blocks controlled by each lock, using the ! choice. This has advantages over default DBA locking because with the default, you would need to acquire a million locks in order to read 1 million blocks. When you lot group the blocks you reduce the number of locks allocated by the grouping factor. Thus a grouping of !ten would mean that you lot would only have to acquire one tenth as many PCM locks as with the default. Performance improves due to the dramatically reduced amount of lock allocation. As a rule of thumb, operation with a group of !10 might be comparable to the speed of hashed locking.
To speed up parallel DML operations, consider using hashed locking rather than DBA locking. A parallel server process works on non-overlapping partitions; it is recommended that partitions not share files. You can thus reduce the number of lock operations by having but one hashed lock per file. Since the parallel server process only works on non-overlapping files, in that location will exist no lock pings.
The following guidelines impact retentiveness usage, and thus indirectly bear upon performance:
- Never classify PCM locks for datafiles of temporary tablespaces.
- Never allocate PCM locks for datafiles that contain only rollback segments. These are protected by GC_ROLLBACK_LOCKS and GC_ROLLBACK_SEGMENTS.
- Classify specific PCM locks for the Organization tablespace. This practise ensures that information lexicon activity such as infinite management never interferes with the information tablespaces at a cache management level (fault 1575).
For example, on a read-only database with a information warehousing awarding's query-only workload, you lot might create 500 PCM locks on the SYSTEM tablespace in file 1, then create 50 more locks to be shared for all the data in the other files. Infinite direction piece of work will so never interfere with the rest of the database.
See Likewise: Oracle8 Parallel Server Concepts & Administration for a thorough give-and-take of PCM locks and locking parameters.
Resource allotment of Processes and Instances
Parallel execution assigns each case a unique number, which is determined by the INSTANCE_NUMBER initialization parameter. The instance number regulates the society of instance startup.
Note: For Oracle Parallel Server, the PARALLEL_INSTANCE_GROUP parameter determines what instance group volition be used for a particular functioning. For more information, see Oracle8 Parallel Server Concepts & Administration.
Oracle computes a target degree of parallelism past examining the maximum of the degree for each table and other factors, before run time. At run fourth dimension, a parallel performance is executed sequentially if insufficient parallel server processes are bachelor. PARALLEL_MIN_PERCENT sets the minimum percentage of the target number of parallel server processes that must be available in lodge for the operation to run in parallel. When PARALLEL_MIN_PERCENT is set to n, an mistake message is sent if n per centum parallel server processes are not available. If no parallel server processes are available, a parallel operation is executed sequentially.
Load Balancing for Multiple Concurrent Parallel Operations
Load balancing is the distribution of parallel server processes to achieve even CPU and retentivity utilization, and to minimize remote I/O and communication betwixt nodes.
When multiple concurrent operations are running on a single node, load balancing is done by the operating organization. For example, if there are x CPUs and 5 parallel server processes, the operating system distributes the v processes among the CPUs. If a second node is added, the operating system notwithstanding distributes the workload.
For a parallel server, however, no single operating system performs the load balancing: instead, parallel execution performs this function.
If an operation requests more than than one instance, allocation priorities involve table caching and deejay affinity.
Thus, if there are 5 parallel server processes, it is advantageous for them to run on as many nodes as possible.
In Oracle Server release 8.0, allocation of processes and instances is based on case groups. With example groups a parallel server system will exist partitioned into disjoint logical subsystems. Parallel resource volition be allocated out of a particular instance group only if the parallel coordinator is role of the group. This arroyo supports application and data partitioning.
Encounter Also: Oracle8 Parallel Server Concepts & Assistants for more than information about instance groups.
Deejay Affinity
Some Oracle Parallel Server platforms use disk analogousness. Without disk analogousness, Oracle tries to residuum the allocation evenly beyond instances; with disk affinity, Oracle tries to allocate parallel server processes for parallel table scans on the instances that are closest to the requested information. Deejay affinity minimizes data shipping and internode communication on a shared goose egg architecture. It can significantly increase parallel operation throughput and decrease response time.
Disk affinity is used for parallel table scans, parallel temporary tablespace allocation, parallel DML, and parallel index scan. It is not used for parallel table creation or parallel index cosmos. Access to temporary tablespaces preferentially uses local datafiles. It guarantees optimal space direction extent resource allotment. Disks striped by the operating organization are treated by deejay affinity every bit a single unit of measurement.
In the following example of deejay affinity, table T is distributed across 3 nodes, and a full table browse on tabular array T is being performed.
Effigy 20-3 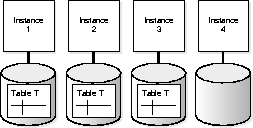 Disk Affinity Example
Disk Affinity Example
- If a query requires two instances, and so two instances from the fix 1, 2, and 3 are used.
- If a query requires 3 instances, so instances 1, two, and 3 are used.
- If a query requires four instances, then all 4 instances are used.
- If there are two concurrent operations confronting table T, each requiring 3 instances (and enough processes are available on the instances for both operations), then both operations will employ instances one, two, and iii. Instance four volition not be used. In contrast, without disk affinity instance 4 would be used.
Resource Timeout
A parallel DML transaction spanning Oracle Parallel Server instances may be waiting as well long for a resources due to potential deadlock involving this transaction and other parallel or non-parallel DML transactions. Set the PARALLEL_TRANSACTION_RESOURCE_TIMEOUT parameter to specify how long a parallel DML transaction should wait for a resources before aborting.
See Also: Oracle8 SQL Reference
Parallel Execution Tuning Techniques
This department describes operation techniques for parallel operations.
- Overriding the Default Caste of Parallelism
- Rewriting SQL Statements
- Creating and Populating Tables in Parallel
- Creating Indexes in Parallel
- Refreshing Tables in Parallel
- Using Hints with Cost Based Optimization
- Tuning Parallel Insert Performance
Overriding the Default Degree of Parallelism
The default degree of parallelism is appropriate for reducing response time while guaranteeing use of CPU and I/O resources for any parallel operations. If an operation is I/O bound, you should consider increasing the default degree of parallelism. If it is memory bound, or several concurrent parallel operations are running, consider decreasing the default degree.
Oracle uses the default caste of parallelism for tables that have PARALLEL attributed to them in the data dictionary, or when the PARALLEL hint is specified. If a table does not take parallelism attributed to it, or has NOPARALLEL (the default) attributed to it, and so that tabular array is never scanned in parallel-regardless of the default degree of parallelism that would be indicated by the number of CPUs, instances, and devices storing that table.
Use the post-obit guidelines when adjusting the degree of parallelism:
- You tin adjust the caste of parallelism either by using ALTER Table or by using hints.
- To increase the number of concurrent parallel operations, reduce the caste of parallelism.
- For I/O-bound parallel operations, beginning spread the data over more disks than there are CPUs. And then, increase parallelism in stages. Stop when the query becomes CPU bound.
For example, assume a parallel indexed nested loop join is I/O spring performing the alphabetize lookups, with #CPUsouthward=10 and #disks=36. The default caste of parallelism is 10, and this is I/O jump. You lot could first endeavour parallel degree 12. If still I/O jump, you could attempt parallel caste 24; if notwithstanding I/O bound, you could effort 36.
To override the default degree of parallelism:
- Determine the maximum number of query servers your system can support.
- Divide the parallel server processes among the estimated number of concurrent queries.
Rewriting SQL Statements
The most important issue for parallel query execution is ensuring that all parts of the query plan that process a substantial amount of data execute in parallel. Employ EXPLAIN PLAN to verify that all plan steps have an OTHER_TAG of PARALLEL_TO_PARALLEL, PARALLEL_TO_SERIAL, PARALLEL_COMBINED_WITH_PARENT, or PARALLEL_COMBINED_WITH_CHILD. Any other keyword (or cipher) indicates series execution, and a possible bottleneck.
By making the following changes you can increase the optimizer's ability to generate parallel plans:
- Catechumen subqueries, especially correlated subqueries, into joins. Oracle can parallelize joins more than efficiently than subqueries. This also applies to updates.
- Use a PL/SQL function in the WHERE clause of the master query, instead of a correlated subquery.
- Rewrite queries with distinct aggregates every bit nested queries. For instance, rewrite
SELECT COUNT(DISTINCT C) FROM T;
to
SELECT COUNT(*)FROM (SELECT DISTINCT C FROM T);
Run across Also: "Updating the Table" on folio 20-22
Creating and Populating Tables in Parallel
Oracle cannot return results to a user process in parallel. If a query returns a large number of rows, execution of the query may indeed be faster; yet, the user process can merely receive the rows serially. To optimize parallel query functioning with queries that recollect large result sets, use PARALLEL CREATE Tabular array ... AS SELECT or direct-load insert to store the upshot set in the database. At a later time, users tin can view the effect set serially.
Note: Parallelism of the SELECT does non influence the CREATE statement. If the CREATE is parallel, however, the optimizer tries to make the SELECT run in parallel likewise.
When combined with the NOLOGGING pick, the parallel version of CREATE TABLE ... As SELECT provides a very efficient intermediate table facility.
For example:
CREATE TABLE summary PARALLEL NOLOGGING Every bit SELECT dim_1, dim_2 ..., SUM (meas_1) FROM facts Grouping Past dim_1, dim_2;
These tables can as well exist incrementally loaded with parallel insert. You can take reward of intermediate tables using the following techniques:
- Common subqueries can be computed once and referenced many times. This may exist much more efficient than referencing a complex view many times.
- Decompose complex queries into simpler steps in order to provide application-level checkpoint/restart. For instance, a complex multi-table join on a database one terabyte in size could run for dozens of hours. A crash during this query would mean starting over from the get-go. Using CREATE Table ... Every bit SELECT and/or PARALLEL INSERT AS SELECT, you can rewrite the query as a sequence of simpler queries that run for a few hours each. If a system failure occurs, the query can exist restarted from the last completed footstep.
- Materialize a Cartesian product. This may allow queries against star schemas to execute in parallel. It may also increase scalability of parallel hash joins past increasing the number of singled-out values in the join column.
Consider a huge table of retail sales data that is joined to region and to department lookup tables. There are 5 regions and 25 departments. If the huge table is joined to regions using parallel hash sectionalisation, the maximum speedup is 5. Similarly, if the huge table is joined to departments, the maximum speedup is 25. But if a temporary table containing the Cartesian product of regions and departments is joined with the huge tabular array, the maximum speedup is 125.
- Efficiently implement manual parallel deletes by creating a new table that omits the unwanted rows from the original table, and then dropping the original table. Alternatively, yous can use the convenient parallel delete feature, which tin can straight delete rows from the original table.
- Create summary tables for efficient multidimensional drill-down analysis. For example, a summary tabular array might store the sum of acquirement grouped past calendar month, brand, region, and salesperson.
- Reorganize tables, eliminating chained rows, compressing costless space, and and so on, by copying the old table to a new table. This is much faster than export/import and easier than reloading.
Annotation: Exist certain to use the Analyze command on newly created tables. Too consider creating indexes. To avert I/O bottlenecks, specify a tablespace with at least every bit many devices as CPUs. To avert fragmentation in allocating space, the number of files in a tablespace should be a multiple of the number of CPUs.
Creating Indexes in Parallel
Multiple processes can piece of work together simultaneously to create an index. By dividing the work necessary to create an index among multiple server processes, the Oracle Server tin can create the index more than speedily than if a single server process created the index sequentially.
Parallel alphabetize creation works in much the aforementioned fashion every bit a tabular array scan with an Club Past clause. The table is randomly sampled and a fix of index keys is found that equally divides the index into the aforementioned number of pieces as the degree of parallelism. A first fix of query processes scans the tabular array, extracts central,ROWID pairs, and sends each pair to a procedure in a second set of query processes based on key. Each process in the second set sorts the keys and builds an index in the usual fashion. Afterward all index pieces are built, the parallel coordinator simply concatenates the pieces (which are ordered) to form the last index.
Parallel local index creation uses a unmarried server set. Each server procedure in the set is assigned a table sectionalization to scan, and to build an alphabetize partition for. Because half as many server processes are used for a given degree of parallelism, parallel local index creation tin can exist run with a higher caste of parallelism.
You can optionally specify that no redo and disengage logging should occur during index creation. This tin significantly improve operation, just temporarily renders the alphabetize unrecoverable. Recoverability is restored after the new index is backed up. If your application tin can tolerate this window where recovery of the index requires it to exist re-created, then you should consider using the NOLOGGING pick.
The PARALLEL clause in the CREATE Alphabetize command is the only fashion in which you lot can specify the caste of parallelism for creating the index. If the caste of parallelism is non specified in the parallel clause of CREATE INDEX, then the number of CPUs is used as the caste of parallelism. If in that location is no parallel clause, index creation will exist washed serially.
Attention: When creating an index in parallel, the STORAGE clause refers to the storage of each of the subindexes created by the query server processes. Therefore, an index created with an INITIAL of 5MB and a PARALLEL DEGREE of 12 consumes at to the lowest degree 60MB of storage during index creation because each procedure starts with an extent of 5MB. When the query coordinator process combines the sorted subindexes, some of the extents may exist trimmed, and the resulting index may be smaller than the requested 60MB.
When you lot add together or enable a UNIQUE key or Principal KEY constraint on a table, you cannot automatically create the required alphabetize in parallel. Instead, manually create an index on the desired columns using the CREATE Index command and an appropriate PARALLEL clause and and then add or enable the constraint. Oracle then uses the existing index when enabling or adding the constraint.
Multiple constraints on the same table can be enabled concurrently and in parallel if all the constraints are already in the enabled novalidate land. In the post-obit example, the Alter Tabular array ... ENABLE CONSTRAINT statement performs the table scan that checks the constraint in parallel:
CREATE Table a (a1 NUMBER CONSTRAINT ach CHECK (a1 > 0) ENABLE NOVALIDATE) PARALLEL 5; INSERT INTO a values (ane); COMMIT; Change Table a ENABLE CONSTRAINT ach;
- Meet Besides: For more information on how extents are allocated when using the parallel query feature, see Oracle8 Concepts.
- Refer to the Oracle8 SQL Reference for the consummate syntax of the CREATE INDEX command.
Refreshing Tables in Parallel
Parallel DML combined with the updatable join views facility provides an efficient solution for refreshing the tables of a data warehouse system. To refresh tables is to update them with the differential data generated from the OLTP production system.
In the post-obit case, assume that you want to refresh a table named CUSTOMER(c_key, c_name, c_addr). The differential information contains either new rows or rows that take been updated since the last refresh of the data warehouse. In this example, the updated information is shipped from the product system to the data warehouse system by means of ASCII files. These files must be loaded into a temporary tabular array, named DIFF_CUSTOMER, before starting the refresh process. You can use SQL Loader with both the parallel and directly options to efficiently perform this task.
In one case DIFF_CUSTOMER is loaded, the refresh procedure tin exist started. It is performed in ii phases:
- updating the table
- inserting the new rows in parallel
Updating the Table
A straightforward SQL implementation of the update uses subqueries:
UPDATE customer SET(c_name, c_addr) = (SELECT c_name, c_addr FROM diff_customer WHERE diff_customer.c_key = customer.c_key) WHERE c_key IN(SELECT c_key FROM diff_customer);
Unfortunately, the two subqueries in the preceding statement affect the functioning.
An alternative is to rewrite this query using updatable join views. To practise this you must first add a primary central constraint to the DIFF_CUSTOMER table to ensure that the modified columns map to a key-preserved table:
CREATE UNIQUE INDEX diff_pkey_ind on diff_customer(c_key) PARALLEL NOLOGGING; Change Table diff_customer Add Primary Cardinal (c_key);
The Client tabular array can and so be updated with the post-obit SQL argument:
UPDATE /*+PARALLEL(customer,12)*/ customer (SELECT customer.c_name every bit c_name,customer.c_addr equally c_addr, diff_customer.c_name as c_newname, diff_customer.c_addr every bit c_newaddr FROM customer, diff_customer WHERE client.c_key = diff_customer.c_key) Set up c_name = c_newname, c_addr = c_newaddr;
If the Client table is partitioned, parallel DML can be used to farther improve the response time. It could non be used with the original SQL statement because of the subquery in the Fix clause.
- See Also: "Rewriting SQL Statements" on page twenty-xviii
- Oracle8 Application Developer's Guide for data nearly key-preserved tables
Inserting the New Rows into the Tabular array in Parallel
The final phase of the refresh process consists in inserting the new rows from the DIFF_CUSTOMER to the CUSTOMER table. Unlike the update instance, you cannot avoid having a subquery in the insert statement:
INSERT /*+PARALLEL(customer,12)*/ INTO customer SELECT * FROM diff_customer WHERE diff_customer.c_key NOT IN (SELECT /*+ HASH_AJ */ key FROM customer);
Simply here, the HASH_AJ hint transforms the subquery into an anti-hash bring together. (The hint is non required if the parameter ALWAYS_ANTI_JOIN is set to hash in the initialization file). Doing so allows y'all to use parallel insert to execute the preceding statement very efficiently. Notation that parallel insert is applicative even if the table is not partitioned.
Using Hints with Cost Based Optimization
Cost-based optimization is a highly sophisticated approach to finding the all-time execution program for SQL statements. Oracle automatically uses cost-based optimization with parallel execution.
Attention: You must use Clarify to gather electric current statistics for cost-based optimization. In particular, tables used in parallel should always be analyzed. Always go along your statistics current by running Clarify after DDL and DML operations.
Apply discretion in employing hints. If used, hints should come up as a last stride in tuning, and only when they demonstrate a necessary and significant performance advantage. In such cases, begin with the execution programme recommended by cost-based optimization, and get on to test the effect of hints only after you lot have quantified your performance expectations. Call back that hints are powerful; if you apply them and the underlying data changes you may need to modify the hints. Otherwise, the effectiveness of your execution plans may deteriorate.
Always apply cost-based optimization unless y'all accept an existing application that has been hand-tuned for rule-based optimization. If you must utilize dominion-based optimization, rewriting a SQL statement can give orders of magnitude improvements.
Annotation: If whatsoever tabular array in a query has a parallel caste greater than one (including the default degree), Oracle uses the cost-based optimizer for that query-fifty-fifty if OPTIMIZER_MODE = RULE, or if in that location is a Dominion hint in the query itself.
See Also: "OPTIMIZER_PERCENT_PARALLEL" on folio xix-5. This parameter controls parallel awareness.
Tuning Parallel Insert Functioning
This section provides an overview of parallel operation functionality.
- INSERT
- Direct-Load INSERT
- Parallelizing INSERT, UPDATE, and DELETE
- Run into Also: Oracle8 Concepts for a detailed discussion of parallel Data Manipulation Language and caste of parallelism.
- For a discussion of parallel DML affinity, delight see Oracle8 Parallel Server Concepts & Administration.
INSERT
Oracle8 INSERT functionality can be summarized as follows:
Table 20-iii Summary of INSERT Features
| Insert Type | Parallel | Serial | NOLOGGING |
| Conventional | No | Yeah | No |
| Directly Load Insert (Append) | Aye: requires * Alter SESSION ENABLE PARALLEL DML * Table PARALLEL attribute or PARALLEL hint * APPEND hint (optional) | Aye: requires * Append hint | Yes: requires * NOLOGGING aspect fix for table or partitioning |
If parallel DML is enabled and at that place is a PARALLEL hint or PARALLEL aspect set for the table in the information dictionary, then inserts will be parallel and appended, unless a restriction applies. If either the PARALLEL hint or PARALLEL attribute is missing, and then the insert is performed serially.
Direct-Load INSERT
Append mode is the default during a parallel insert: data is always inserted into a new block which is allocated to the tabular array. Therefore the Append hint is optional. You should utilize suspend mode to increase the speed of insert operations-simply not when space utilization needs to exist optimized. You tin use NOAPPEND to override append mode.
Note that the APPEND hint applies to both series and parallel insert: even serial insert volition be faster if you use information technology. Append, however, does crave more space and locking overhead.
Y'all can use NOLOGGING with Suspend to make the procedure fifty-fifty faster. NOLOGGING means that no redo log is generated for the operation. NOLOGGING is never the default; use information technology when you wish to optimize performance. It should not ordinarily be used when recovery is needed for the tabular array or partition. If recovery is needed, be sure to accept a backup immediately after the operation. Apply the ALTER TABLE [NO]LOGGING statement to fix the appropriate value.
See Also: Oracle8 Concepts
Parallelizing INSERT, UPDATE, and DELETE
When the table or partition has the PARALLEL attribute in the data dictionary, that attribute setting is used to make up one's mind parallelism of UPDATE and DELETE statements equally well as queries. An explicit PARALLEL hint for a table in a statement overrides the issue of the PARALLEL attribute in the data dictionary.
You can apply the NOPARALLEL hint to override a PARALLEL attribute for the table in the data dictionary. Note, in general, that hints take precedence over attributes.
DML operations are considered for parallelization only if the session is in a PARALLEL DML enabled fashion. (Use ALTER SESSION ENABLE PARALLEL DML to enter this mode.) The mode does non affect parallelization of queries or of the query portions of a DML argument.
See Likewise: Oracle8 Concepts for more information on parallel INSERT, UPDATE and DELETE.
Parallelizing INSERT ... SELECT
In the INSERT... SELECT statement you can specify a PARALLEL hint after the INSERT keyword, in improver to the hint after the SELECT keyword. The PARALLEL hint later on the INSERT keyword applies to the insert operation only, and the PARALLEL hint after the SELECT keyword applies to the select performance only. Thus parallelism of the INSERT and SELECT operations are independent of each other. If 1 operation cannot exist performed in parallel, it has no result on whether the other functioning tin be performed in parallel.
The ability to parallelize INSERT causes a alter in existing behavior, if the user has explicitly enabled the session for parallel DML, and if the table in question has a PARALLEL attribute set in the information lexicon entry. In that case existing INSERT ... SELECT statements that take the select operation parallelized may too take their insert operation parallelized.
Note as well that if you query multiple tables, you can specify multiple SELECT PARALLEL hints and multiple PARALLEL attributes.
Example
Add the new employees who were hired after the acquisition of Summit.
INSERT /*+ PARALLEL(emp,4) */ INTO emp SELECT /*+ PARALLEL(acme_emp,iv) */ * FROM acme_emp;
The APPEND keyword is not required in this case, because it is implied by the PARALLEL hint.
Parallelizing UPDATE and DELETE
The PARALLEL hint (placed immediately afterward the UPDATE or DELETE keyword) applies not merely to the underlying scan functioning, but as well to the update/delete functioning. Alternatively, you tin can specify update/delete parallelism in the PARALLEL clause specified in the definition of the table to be modified.
If you accept explicitly enabled parallel DML for the session or transaction, UPDATE/DELETE statements that have their query operation parallelized may also take their UPDATE/DELETE operation parallelized. Any subqueries or updatable views in the argument may have their own separate parallel hints or clauses, but these parallel directives practise not affect the decision to parallelize the update or delete. If these operations cannot be performed in parallel, it has no upshot on whether the UPDATE or DELETE portion can exist performed in parallel.
Parallel UPDATE and DELETE can exist done simply on partitioned tables.
Case 1
Requite a 10% salary heighten to all clerks in Dallas.
UPDATE /*+ PARALLEL(emp,five) */ emp Set up sal=sal * ane.1 WHERE job='CLERK' and deptno in (SELECT deptno FROM dept WHERE location='DALLAS');
The PARALLEL hint is applied to the update functioning equally well as to the scan.
Example 2
Fire all employees in the accounting department, which will now be outsourced.
DELETE /*+ PARALLEL(emp,two) */ FROM emp WHERE deptno IN (SELECT deptno FROM dept WHERE dname='ACCOUNTING');
Again, the parallelism will be practical to the scan as well equally update performance on table EMP.
Additional PDML Examples
The following examples show the apply of parallel DML.
Note: Equally these examples demonstrate, y'all must enable parallel DML before using the PARALLEL or Append hints. You must issue a COMMIT or ROLLBACK control immediately after executing parallel INSERT, UPDATE, or DELETE. You can effect no other SQL commands before committing or rolling dorsum.
The following statement enables parallel DML:
ALTER SESSION ENABLE PARALLEL DML;
Serial too equally parallel straight-load insert requires commit or rollback immediately afterwards.
INSERT /*+ Suspend NOPARALLEL(table1) */ INTO table1
A select statement issued at this point would fail, with an error bulletin, considering no SQL can be performed before a COMMIT or ROLLBACK is issued.
ROLLBACK;
Afterwards this ROLLBACK, a SELECT statement will succeed:
SELECT * FROM 5$PQ_SESSTAT;
Parallel update too requires commit or rollback immediately subsequently:
UPDATE /*+ PARALLEL(table1,2) */ table1 SET col1 = col1 + i; COMMIT; SELECT * FROM V$PQ_SESSTAT;
Every bit does parallel delete:
DELETE /*+ PARALLEL(table3,2) */ FROM table3 WHERE col2 < five; COMMIT; SELECT * FROM 5$PQ_SESSTAT;
Source: https://docs.oracle.com/cd/A58617_01/server.804/a58246/pexunder.htm
0 Response to "Turn Parallel Processing Off and Run Sequentially Again"
Post a Comment